- Зайти в раздел dev_tools в кибане
- Выполнить следующие запросы:
Размер только primary шардов
GET /<index-pattern>/_stats?filter_path=_all.primaries.store.size_in_bytes
(primary + replica)
GET /<index-pattern>/_stats?filter_path=_all.total.store.size_in_bytes
Пример по всем индексам команды team01. index-pattern = team01* (1 primary, 1 replica)
GET /team01*/_stats?filter_path=_all.primaries.store.size_in_bytes
{
"_all" : {
"primaries" : {
"store" : {
"size_in_bytes" : 42532218148
}
}
}
}
GET /team01*/_stats?filter_path=_all.total.store.size_in_bytes
{
"_all" : {
"total" : {
"store" : {
"size_in_bytes" : 84966271409
}
}
}
}
В памяти всех мастер-нод находится состояние кластера (cluster state), в котором хранятся метаданные о:
- нодах
- индексах
- шардах
- распределении (allocation) шардов
- маппинги и настройки индексов
- другое (скрипты, роутинг и пр. настройки)
Поэтому чем больше становится этих компонентов, тем больше становится потребление памяти на мастерах
В чём проблема
Из-за того, что индексный файл helm репы bitnami стал весить слишком много (23МБ+ на момент написания этой заметки), разработчики стали “выкидывать” оттуда старые версии чартов
Что делать
Полный индекс со всеми версиями можно забирать из специальной ветки на гитхабе
Для этого надо заменить url helm репозитория https://charts.bitnami.com/bitnami на https://raw.githubusercontent.com/bitnami/charts/archive-full-index/bitnami
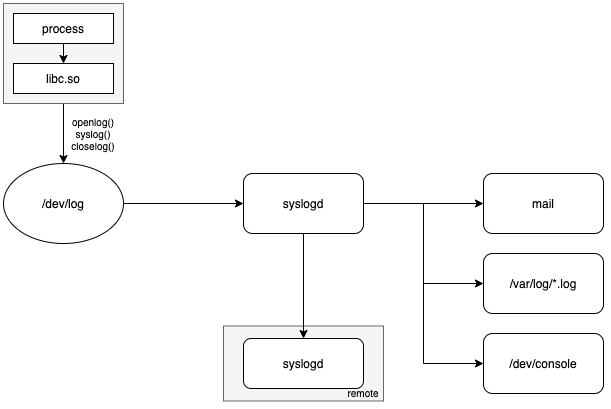
Оригинальный syslogd
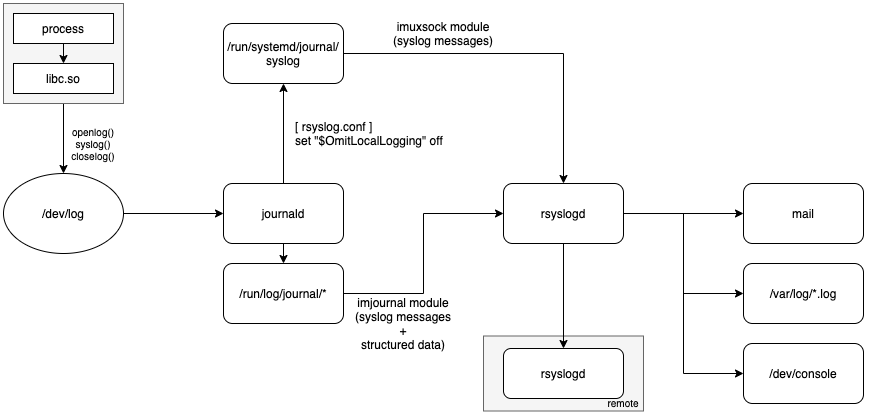
Cвязка journald + rsyslogd
Форматы syslog сообщений
RFC 3164 (устаревший)
RFC 3164 - The BSD Syslog Protocol
Описание формата сообщения
The first part is called the PRI, the second part is the HEADER, and the third part is the MSG. The total length of the packet MUST be 1024 bytes or less
Варианты запуска сборок
Shell executor
- Небезопасно, т.к. можно выполнять какие угодно docker команды на хосте, в т.ч. пробрасывать хостовые папки и запускать privileged контейнеры
docker-in-docker
- Изолированные друг от друга контейнеры, т.к. здесь child контейнеры от контейнера dind, а не от хостового docker.sock
- Необходим запуск с privileged (небезопасно)
Проброс docker.sock
- Все контейнеры - siblings (видят друг друга), т.к. запускается через хостовый docker
- Небезопасно, т.к. можно выполнять какие угодно docker команды на хосте, в т.ч. пробрасывать хостовые папки и запускать privileged контейнеры
buildah/buildkit/img
- Позволяют внутри докер контейнера запускать сборку образа без докер-демона
- Требуется unprivileged_userns_clone (user namespaces), у которого свои security-риски
- Синтаксис запуска отличается -> переучивать команду
kaniko
- Позволяют внутри докер контейнера запускать сборку образа без докер-демона
- Не поддерживается установка бинарника в свой образ. Необходимо использовать официальный образ
- Синтаксис запуска отличается -> переучивать команду
Потенциальные векторы атаки
Источник
- В сборке используется публичный образ, в котором в entrypoint выполняется команда проверки docker.sock и запуск контейнера через него
- При сборке в зависимостях (напрмер, node) скачивается зловред, который запускается в процессе сборки. Далее проверка docker.sock и запуск контейнера через него
Цель
- Закрепиться в системе. Через докер возможно установить свои бинарники и сервисы в систему
- Дальнейший скан сети и поиск уязвимостей для распространения и закрепления
- Пользователь генерит csr и передаёт администратору кластера
openssl req -new -newkey rsa:2048 -nodes -keyout i.ivanov.key.pem -out i.ivanov.csr -subj "/CN=i.ivanov /O=MY.ORG" - Администратор кластера создаёт манифест CSR в kubernetes, где сертификат закодирован в base64
cat <<EOF | kubectl apply -f - apiVersion: certificates.k8s.io/v1 kind: CertificateSigningRequest metadata: name: i.ivanov spec: request: <CSR_CONTENT> signerName: kubernetes.io/kube-apiserver-client usages: - client auth EOF - Администратор кластера выпускает сертификат, подписанный куберовским CA
kubectl certificate approve i.ivanov - Администратор кластера копирует полученный сертификат и пересылает его пользователю. Подтвержденный csr хранится в течение часа
kubectl get csr/i.ivanov -o json | jq -r '.status.certificate' | base64 -D > i.ivanov.crt.pem - Пользователь добавляет в свой локальный ~/.kube/config настройки для кластера. Администратор передаёт значения certificate-authority-data, server, client-certificate-data (п. 4) пользователю.
- Управление доступом пользователей осуществляется через RBAC
Перезапустить kubelet
Контейнеры продолжают работать, но в момент синхронизации состояния подов с api-server поды могут переходить в состояние 0/1 Running, когда трафик на них перестаёт направляться
Остановить kubelet
Нода переходит в состояние NotReady, никаких событий на подах не происходит - они продолжают пребывать в состоянии 1/1 Running, но трафик на них перестаёт идти (из endpoint’ов сервисов удаляются IP адрес подов, которые находятся на “мёртвой” ноде).
Спустя указанный pod-eviction-timeout (5m по-умолчанию) для kube-controller-manager поды переходят в статус Terminating и начинают запускаться на живых воркерках. Поды будут продолжать находиться в статусе Terminating либо до старта kubelet, либо до удаления ноды из кластера. При этом не выгоняются поды DaemonSet и поды, поднятые kubelet’ом(kube-proxy, nginx-proxy, kube-flannel, nodelocaldns и т.п.)
Атуально для Akka HTTP начиная с версии 10.2.0
Github Issue: Add coordinated shutdown support
По-умолчанию, Akka при завершении (в т.ч. получении SIGTERM) запускает процесс Coordinated Shutdown, в рамках которого происходят последовательно несколько фаз:
- before-service-unbind
- service-unbind
- service-requests-done
- service-stop
- before-cluster-shutdown
- cluster-sharding-shutdown-region
- cluster-leave
- cluster-exiting
- cluster-exiting-done
- cluster-shutdown
- before-actor-system-terminate
- actor-system-terminate
В каждой фазе выполняются определённые действия и настроен таймаут, который можно переопределить и в течение которого эти действия должны завершиться. Если действия не успевают завершаться, то фаза заканчивается и начинается следующая
В рамках Akka HTTP нас в первую очередь интересуют следующие фазы
- service-unbind #перестаёт слушаться tcp порт и перестают приниматься новые соединения. Установленные соединения не разрываются
- service-requests-done #ожидается окончание запросов, которые в данный момент обрабатываются кодом и клиент ожидает на них ответ
- service-stop #закрываются все установленные соединения
По-умолчанию (default-phase-timeout = 5s), после unbind есть 5 секунд на завершение текущих запросов
При использовании Kubernetes, стоит принимать во внимание также его таймаут terminationGracePeriodSeconds, в течение которого будет ожидаться реакция на SIGTERM, после чего будет послан SIGKILL. По-умолчанию, он равен 30s
Немного о RBAC
В kubernetes есть сущность, которая называется RoleBinding. Она определяет, каким субъектам какая роль будет назначена. RoleBinding действует в рамках namespace, в котором она создана. Для разрешения действий во всех namespace без ограничений необходимо создавать ClusterRoleBinding, который является cluster-wide объектом.
Пример RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: edit
namespace: project-a-devel
subjects:
- kind: Group
name: sre
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.io
Эта роль:
- Действует в рамках namespace
project-a-devel- (metadata:) - Применяется к пользователям в группе
sre(/O=sre) - (subjects:) - Разрешает действия, описанные в созданной по-умолчанию кластерной роли (ClusterRole)
edit- (roleRef:)
Пайплайны для Merge Requests существуют отдельно (имеют лейбл detached) и запускается независимо от основного pipeline. Из-за этого если сделать push в репу в ветку, из которой в гитлабе есть открытый МР, то запускаются 2 одинаковых пайплайна
 Есть варианта, чтобы это избежать:
Есть варианта, чтобы это избежать:
- Дублировать все джобы через extends, чтобы разделить на запускаемые на МРах и на обычные
- Не запускать CI на некоторых ветках, пока из них нет открытого МРа
