Эта статья на Хабре https://habr.com/ru/articles/783586/
Введение
Зачем?
Представим ситуацию, что мы деплоим по push-модели. В качестве платформы для запуска деплоя у нас используется Gitlab: в нём настроен пайплайн и джобы, разворачивающие приложения в разные окружения в Kubernetes
Какой бы инструмент мы не использовали (kubectl, helm), для манипуляций с ресурсами API нам в любом случае будет необходимо аутентифицироваться при выполнении запросов к Kubernetes. Для этого в запросе надо передать данные для аутентификации, будь то токен или сертификат. И тут возникает несколько вопросов:
Где хранить эти креды?
Хранить креды от кластера можно в Gitlab CI/CD Variables и подставлять в джобу деплоя, но тогда потенциально все пользователи будут деплоить с одними и теми же доступами
Как сделать так, чтобы у каждого пользователя были свои данные для доступа в кластер?
Можно было бы вручную запускать джобы деплоя и в параметры каждый раз подставлять свои аутентификационные данные, но, очевидно, такой подход неудобен и подходит далеко не всем
А что если сделать так, чтобы в качестве провайдера аутентификационных данных для Kubernetes выступал сам Gitlab? Тогда не надо было бы нигде хранить креды, и каждый пользователь мог бы аутентифицироваться в кубере под своей учёткой при запуске деплоя
Получить список всех образов и их тегов из docker registry
- Установить утилиту crane
- При необходимости залогиниться в registry с помощью docker или crane
- Выполнить скрипт, формирующий файл со списком
REGISTRY_URL="registry.home.arpa"
cat /dev/null > catalog.txt
for image in $(crane catalog ${REGISTRY_URL}); do
for tag in $(crane ls "${REGISTRY_URL}/${image}"); do
echo "${REGISTRY_URL}/${image}:${tag}" >> catalog.txt
done
done
- (Опционально) Посчитать количество существующих тегов для каждого образа
cat catalog.txt | awk -F':' '{print $1$2}' | sort -n | uniq -c | sort -k1 -n
Посчитать занимаемое место образами в docker registry
Слои файловой системы могут переиспользоваться в разных образах. Поэтому это примерная информация о занимаемом месте
- Установить утилиту crane
- При необходимости залогиниться в registry с помощью docker или crane
- Посчитать суммарный размер слоёв каждого образа по тегу
REGISTRY_URL="registry.home.arpa"
IMAGE="service01"
cat /dev/null > size_images.txt
for tag in $(crane ls "${REGISTRY_URL}/${IMAGE}"); do
img="${REGISTRY_URL}/${IMAGE}:${tag}"
size="$(crane manifest "${img}" | jq -r '[.layers[].size | tonumber] | add')"
echo "${img} ${size}" >> size_images.txt
done
- При необходимости получить суммарный размер
cat size_images.txt | sort -rn | uniq | awk '{size+=$2;} END{print size;}'
Посчитать, сколько весят и как часто переиспользуются между тегами слои образов
- Установить утилиту crane
- При необходимости залогиниться в registry с помощью docker или crane
- Получить размеры всех слоёв образов для всех тегов
REGISTRY_URL="registry.home.arpa"
IMAGE="service01"
cat /dev/null > layers_size.txt
for tag in $(crane ls "${REGISTRY_URL}/${IMAGE}"); do
img="${REGISTRY_URL}/${IMAGE}:${tag}"
crane manifest "${img}" | jq -r '.layers[] | [.digest, .size] | @tsv' >> layers_size.txt
done
- Получить список уникальных слоёв с размерами этих слоёв и количеством переиспользования
cat layers_size.txt | sort -n | uniq -c | awk '{print $2" "$3/1024/1024" "$1}' | sort -k2 -n > unique_layers_size.txt
Почистить образы из docker registry (на Nexus)
Каждый образ - это некий конечный объект с уникальной sha256 суммой (digest). Образ скачивается указанием его дайджейста. Для удобства на дайджейсты навешивают человекочитаемые теги. Их можно навесить сколько угодно на один дайджест
docker pull centos@sha256:be65f488b7764ad3638f236b7b515b3678369a5124c47b8d32916d6487418ea4 docker pull centos:7.9.2009 docker pull centos:7Чтобы удалить образы, нам нужно удалять их по дайджестам, а затем средствами Nexus подчистить “осиротевшие” теги, которые не ссылаются ни на какой дайджест, после чего выполнить compact blobstore
- Установить утилиту crane
- При необходимости залогиниться в registry с помощью docker или crane
- Сформировать список всех тегов целевого образа
REGISTRY_URL="registry.home.arpa"
IMAGE="service01"
cat /dev/null > all_tags.txt
for tag in $(crane ls "${REGISTRY_URL}/${IMAGE}"); do
echo "${REGISTRY_URL}/${IMAGE}:${tag}" >> all_tags.txt
done
- Сформировать список НУЖНЫХ тегов целевого образа
Тут, по сути, надо из всех тегов выделить те теги, которые нужно оставить. Например, исключить все, которые заканчиваются на PIPELINE_ID (5,6 - значный из gitlab)
grep -vE '^.+[0-9]{5,6}$' all_tags.txt > keep_tags.txt - Получить список уникальных дайджестов для всех тегов
REGISTRY_URL="registry.home.arpa"
IMAGE="service01"
cat /dev/null > all_digests.txt
for image in $(cat all_tags.txt); do
echo "${REGISTRY_URL}/${IMAGE}@$(crane digest $image)" >> all_digests.txt;
done
sort -n all_digests.txt | uniq > all_digests_unique.txt
- Получить список уникальных дайджестов для НУЖНЫХ тегов
REGISTRY_URL="registry.home.arpa"
IMAGE="service01"
cat /dev/null > keep_digests.txt
for image in $(cat keep_tags.txt); do
echo "${REGISTRY_URL}/${IMAGE}@$(crane digest $image)" >> keep_digests.txt;
done
sort -n keep_digests.txt | uniq > keep_digests_unique.txt
- Выбрать из списка всех дайджейстов те, которых нет в списке НУЖНЫХ дайджестов
Флаг -u для uniq после сортировки двух списков выведет только те элементы, которые встречаются только один раз
sort -n all_digests_unique.txt keep_digests_unique.txt | uniq -u > delete_digests.txt - Удалить ненужные дайджесты
for digest in $(cat delete_digests.txt); do
crane delete $digest;
done
- Запустить в Nexus таску для удаления “осиротевших” тегов (Docker - Delete unused manifests)
- Запустить compact соответствующего blobstore (Admin - Compact blob store)
Как получить переменные окружения процесса
Простой ответ: прочитав файл /proc/<pid>/environ
Однако таким образом можно получить только те переменные окружения, которые были заданы на момент создания процесса. Если же во время работы программа меняла/устанавливала новые/удаляла переменные окружения через, например, setenv / unsetenv, то эти изменения в файле отражены не будут. Эти значения можно уже будет достать только из оперативной памяти, либо если текущая программа вызовет другую через fork или exec - в таком случае для нового процесса будет заново проинициализирован /proc/<pid>/environ с переменными окружениям родителя/замещённого процесса
Почему так происходит?
Файл /proc/<pid>/environ находится в директории /proc, которая, по сути, предоставляет доступ к структурам данных ядра в оперативной памяти через специальный драйвер файловой системы procfs
Эта статья на Хабре https://habr.com/ru/post/675728/
Описание проблемы
Дано
- кластер k8s
- много приложений, которые пишут свои логи в stdout/stderr, а контейнерный движок (в данном случае docker) складывает их в файлы
- fluent-bit, запущенный на каждой ноде k8s. Он собирает логи, фильтрует их и отправляет в Loki
- loki - хранилище логов от Grafana Labs
В чём заключается проблема
При просмотре логов через Grafana (источник - Loki) видно, что логи приходят с сильной задержкой или часть логов вообще отсутствует. При просмотре через kubectl logs все логи на месте
Решение проблемы

Settings
Client ID
Уникальный идентификатор клиента
Name
Отображаемое имя (например, в окне согласия (Consent))
Description
Описание
Enabled
Вкл/Выкл
Always Display in Console
Всегда показываться клиента в списках приложений пользователя в Account Management Console
Keycloak Scopes OIDC
default - включен в scopes по-умолчанию
optional - включается в scopes при запроса
consent - отображать в окне согласия при запросе разрешения на аутентификацию у пользователя
scope - добавлять в список scope токена
OIDC
profile
default, consent, scope
mappers:
- profile, name, gender, locale, etc…
Realm Settings
General
Name
Название/ID реалма
Display name
Отображаемое имя
HTML Display name
Отображаемое имя с возможность использования html-тегов (например, добавление лого). Если задано, то имеет приоритет над Display name
Frontend URL
Позволяет для реалма задать отдельное доменное имя. Например, можно сделать такой матчинг
auth.example.com -> sso.example.com/auth/realms/myrealm. Обработкой занимается встроенный веб-сервер. То же самое можно реализовать через reverse-proxy, типа nginx, с установкойHostхидера при проксировании и “обрезанием” путейEnabled
Вкл/Выкл
User-Managed Access
Включить управление своими ресурсами в Account Management Console (auth/realms/myrealm/account/resource)
Endpoints
Ссылки OIDC/SAML, где можно получить все доступные точки входа для проктоколов
Описание
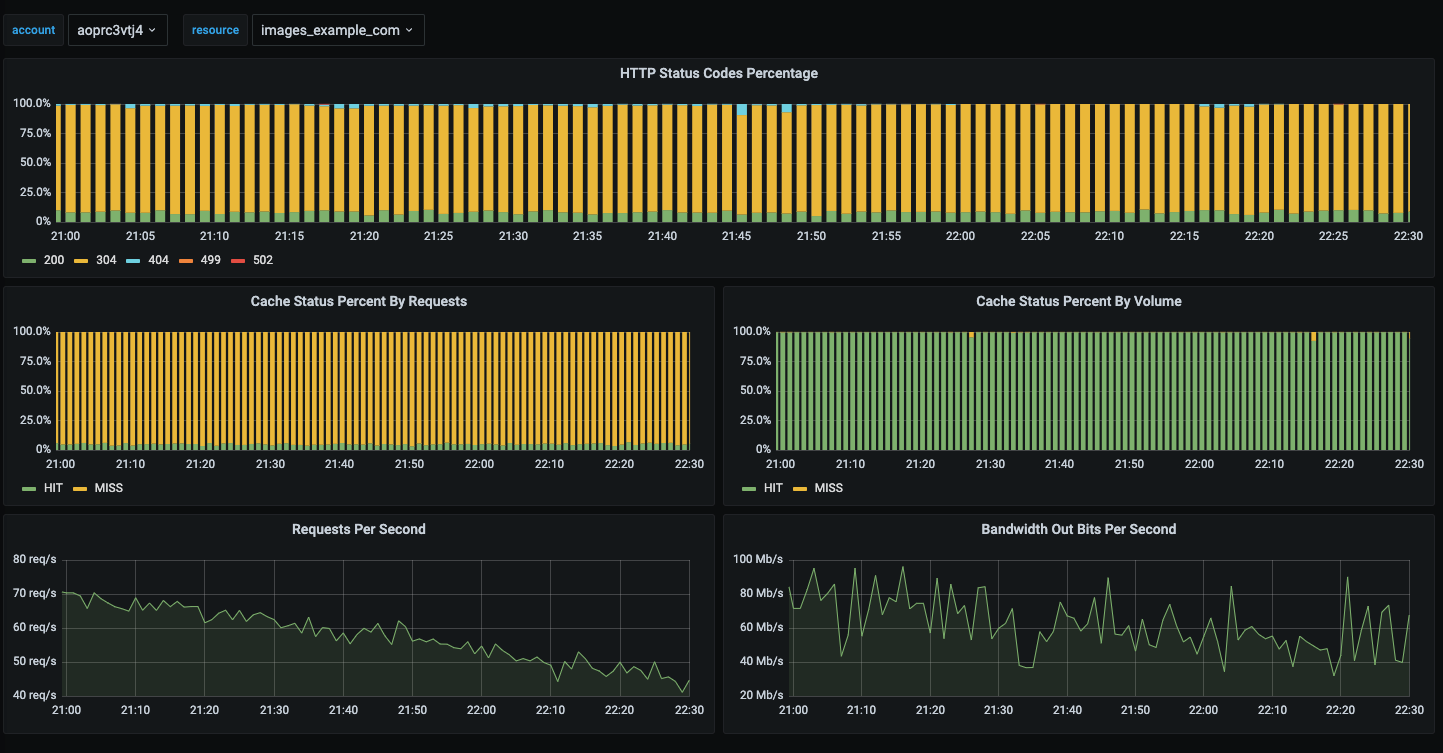
Мы используем CDN для раздачи статичных файлов и хотим иметь статистику по этой раздаче (коды ответов, rps, полосу пропускания)
Первый и самый главный вопрос - откуда получить эти данные? Конечно же из CDN API.
Ищем… Ага! Статистика по конкретному аккаунту с разбивкой по ресурсам
FATAL post-upgrade error: unable to create/update the DNS service: services “kube-dns” not found
https://github.com/kubernetes/kubeadm/issues/2358
Необходимо скопировать текущий манифест сервиса coredns, изменить название на kube-dns, изменить clusterIP так, чтобы он заканчивался на .10 (например, 10.233.0.10) и применить новый манифест. Адрес .10 может уже занят другим сервисам, необходимо его будет освободить
kubectl -n kube-system get svc coredns -o yaml > kube-dns.yaml
# edit kube-dns.yaml
kubectl -n kube-system apply -f kube-dns.yaml
FATAL post-upgrade error: unable to create deployment: Post "https://127.0.0.1:6443/apis/apps/v1/namespaces/kube-system/deployments?timeout=10s": net/http: request canceled (Client.Timeout exceeded while awaiting headers)
Создание ресурса не укладывается в захардкоженный таймаут в 10s. Это может быть по нескольким причинам
- медленная запись на диск через etcd
- в процессе добавления ресурса срабатывает Mutation Webhook (kubectl get mutatingwebhookconfigurations. admissionregistration.k8s.io). Этот хук означает, что надо где-то изменить отправленный в API манифест. Тот сервис, который должен изменить, по какой-то причине делает это медленно или не делает это вообще - необходимо искать проблему там. Временное решение - отключить тот сервис, чтобы не срабатывал вебхук
Это примерный процесс обновления, который проверен на версиях 1.15-1.18 На более поздних версиях этот процесс должен быть сильно проще, особенно в плане обновления сертификата kubelet на master-нодах
На master-нодах
- Обновить сертификаты компонентов кубера с помощью kubeadm
for cert in apiserver apiserver-kubelet-client front-proxy-client admin.conf controller-manager.conf scheduler.conf; do /usr/local/bin/kubeadm alpha certs renew $cert; done - Обновить сертификаты kubelet
#!/bin/bash set -eu -o pipefail ## kubelet kube_dir="/etc/kubernetes" ### v3 extensions settings cat << EOF > ${kube_dir}/v3_ext keyUsage=keyEncipherment,digitalSignature extendedKeyUsage=clientAuth EOF ### get cert and key cat ${kube_dir}/kubelet.conf | grep certificate-data | awk '{print $2}' | base64 -d > ${kube_dir}/kubelet.crt cat ${kube_dir}/kubelet.conf | grep key-data | awk '{print $2}' | base64 -d > ${kube_dir}/kubelet.key ### generate csr and sign it openssl x509 -x509toreq -in ${kube_dir}/kubelet.crt -out ${kube_dir}/kubelet.csr -signkey ${kube_dir}/kubelet.key openssl x509 -req -in ${kube_dir}/kubelet.csr -CA ${kube_dir}/ssl/ca.crt -CAkey ${kube_dir}/ssl/ca.key -CAcreateserial -out ${kube_dir}/kubelet.crt -days 365 -extfile ${kube_dir}/v3_ext ### insert cert to kubelet.conf cert_data=$(cat ${kube_dir}/kubelet.crt | base64 -w0) sed -i "s/client-certificate-data: .*$/client-certificate-data: $cert_data/" ${kube_dir}/kubelet.conf rm -f ${kube_dir}/kubelet.csr ${kube_dir}/kubelet.crt ${kube_dir}/kubelet.key ${kube_dir}/v3_ext
Это же можно сделать проще
/usr/local/bin/kubeadm alpha kubeconfig user --org system:nodes --client-name system:node:$(hostname) >/etc/kubernetes/kubelet.confДля версии >=1.20 можно также задать cluster-name
/usr/local/bin/kubeadm alpha kubeconfig user --org system:nodes --client-name system:node:$(hostname) --cluster-name cluster.local >/etc/kubernetes/kubelet.conf
- Перезапустить docker и kubelet
systemctl restart docker kubelet
На worker-нодах надо что-то делать только если уже не было включено автоматическое обновление
Включить автоматическое обновление сертификата kubelet
grep -Fr rotateCertificates /etc/kubernetes/kubelet-config.yaml || echo "rotateCertificates: true" >> /etc/kubernetes/kubelet-config.yamlПерезапустить kubelet
systemctl restart kubelet
