документация
Немного о RBAC
В kubernetes есть сущность, которая называется RoleBinding. Она определяет, каким субъектам какая роль будет назначена. RoleBinding действует в рамках namespace, в котором она создана. Для разрешения действий во всех namespace без ограничений необходимо создавать ClusterRoleBinding, который является cluster-wide объектом.
Пример RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: edit
namespace: project-a-devel
subjects:
- kind: Group
name: sre
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: edit
apiGroup: rbac.authorization.k8s.io
Эта роль:
- Действует в рамках namespace
project-a-devel- (metadata:) - Применяется к пользователям в группе
sre(/O=sre) - (subjects:) - Разрешает действия, описанные в созданной по-умолчанию кластерной роли (ClusterRole)
edit- (roleRef:)
Пайплайны для Merge Requests существуют отдельно (имеют лейбл detached) и запускается независимо от основного pipeline. Из-за этого если сделать push в репу в ветку, из которой в гитлабе есть открытый МР, то запускаются 2 одинаковых пайплайна
 Есть варианта, чтобы это избежать:
Есть варианта, чтобы это избежать:
- Дублировать все джобы через extends, чтобы разделить на запускаемые на МРах и на обычные
- Не запускать CI на некоторых ветках, пока из них нет открытого МРа
Эта статья на Хабре https://habr.com/ru/post/491108/
Helmfile - обёртка для helm, которая позволяет в одном месте описывать множество helm релизов, параметризовать их чарты для нескольких окружений, а также задавать порядок их деплоя.
О самом helmfile и примерах его использования можно почитать в readme и best practices guide.
Мы же познакомимся с неочевидными способами описать релизы в helmfile
Допустим, у нас есть пачка helm-чартов (для примера пусть будет postgres и некое backend приложение) и несколько окружений (несколько kubernetes кластеров, несколько namespace’ов или несколько и того, и другого). Берём helmfile, читаем документацию и начинаем описывать наши окружения и релизы:
.
├── envs
│ ├── devel
│ │ └── values
│ │ ├── backend.yaml
│ │ └── postgres.yaml
│ └── production
│ └── values
│ ├── backend.yaml
│ └── postgres.yaml
└── helmfile.yaml
![]()
Этот пост - небольшой конспект доклада с Highload Кафка. “Описание одной борьбы” / Денис Карасик (Badoo). Как ясно из заголовка статьи, здесь будет рассказано о некоторых важных параметрах конфигурации брокеров, топиков и producer’ов
Вот что говорит нам man ssh_config про ForwardAgent(перевод):
Agent forwarding нужно включать с осторожностью. Пользователи, которые смогут обойти настройки разрешений файлов на удалённом хосте (в частности для unix-socket агента (ssh-agent)) могут получить доступ к локальному агенту через перенаправленное(forwarded)-соединение. Атакующий не сможет вытащить сами ключи из агента, однако получит возможность проводить с ключами действия, позволяющие ему проходить аутентификацию, используя загруженные в агент идентификаторы
Просто запомните: если ваш бастион(прим. пер.: jump box - сервер-бастион для доступа в закрытый сетевой контур) скомпроментирован, и вы используете SSH agent forwarding, чтобы через него подключаться к другим машинам, то высок риск компроментации и этих удалённых машин.
Вместо этого лучше используйте ProxyCommand или ProxyJump (добавлен в OpenSSH 7.3). В таком случае ssh перенаправит TCP-соединение на удалённую машину через бастион, а само соединение будет установлено с вашей локальной машины. Если кто-нибудь на бастионе попробует провести MITM (man-in-the-middle) атаку на ваше соединение, то ssh об этом предупредит (прим. пер.: видимо, речь идёт о предупреждении об изменившимся ssh fingerprint(отпечатке))

Эта заметка - перепечатка своего ответа на вопрос в сервисе toster.ru
Искал решение для планирование резервных копий различными утилитами на различные хранилища и остановился на backupninja
Умеет по расписанию бэкапить БД и файлы и отправлять их на сторонний сервер разными способами, включая rsync, rdiff, duplicity
В /etc/backup.d/ создаёте конфиги вида 10-db.mysql , 50-ftp.dup
Числа в начале файла описывают очерёдность выполнения в случае одновременного запуска (сначала сдампить базу, а затем заливать из папки с архивом на ftp).
Расширение файла указывает на тип задачи (.mysql - бэкап mysql, .dup - используем duplicity)
Чем отличаются всякие там NodePorts, LoadBalancer и Ingress? Все они дают возможность внешнему трафику попасть в ваш кластер, но дают эту возможность по-разному. Давайте-ка разберёмся, как они это делают и когда какой тип сервиса лучше использовать.
ClusterIP
ClusterIP — это дефолтный тип сервиса в кубах, он поднимает вам сервис внутри кластера на внутрекластеровом IP. Доступа для внешнего трафика нет, только внутри кластера.
YAML для ClusterIP выглядит как-то так:
apiVersion: v1
kind: Service
metadata:
name: my-internal-service
spec:
selector:
app: my-app
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
“Так, ну и зачем же рассказывать нам о ClusterIP, если он не принимает внешний трафик?” — спросите вы. А всё потому, что попасть на этот сервис можно через Kubernetes proxy!

dapp — утилита от российской компании Флант, которая занимается внедрением devops-практик (kubernetes, ci/cd и всё такое, ну вы в курсе) Подробное описание можно прочитать на Хабре, а я бы хотел остановиться на некоторых особенностях работы с ней при сборке образов (здесь и далее под образом подразумевается docker image)
На момент написания статьи актуальная версия dapp 0.36.*
В качестве примера для наглядности и понимания общей картины возьмём за основу немного урезанное содержимое dappfile.yaml из официальной документации
![]()
13 март 2018 года LetsEncrypt наконец объявила, что, они начали поддерживать wildcard-сертификаты. Теперь можно за раз получить сертификат, включащий в себя все субдомены
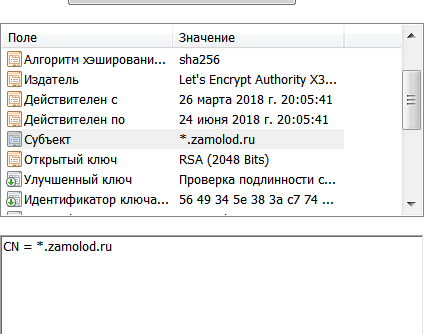
Процесс всё так же автоматизирован через консольную утилиту certbot. Отличие в том, что теперь подтверждение домена можно сделать только через TXT-запись в DNS-зоне, а не через webroot, как раньше.
-
Качаем обновлённый certbot v0.22, разархивируем, переходим в папку
wget 'https://github.com/certbot/certbot/archive/v0.22.2.tar.gz' && \ tar -xvf v0.22.2.tar.gz && \ cd certbot-0.22.2
![]()
По мотивам официального мануала
Скорость переноса данных, по сравнению с обычными консольными dump / restore просто колоссальная, т.к. переносятся целиком файлы таблиц.
Особенность в том, что на целевом сервере не должно быть рабочей mysql с нужными данными
На серверах должен быть установлен Percona XtraBackup
Source server
Делаем частичный бэкап (partial backup), указывая опцию -database, где через пробел перечисляем базы для бэкапа. Важным моментов является то, что необходимо забрать и базу mysql для сохранения учётных записей и разрешений
