документация
Эта статья на Хабре https://habr.com/ru/articles/783586/
Введение
Зачем?
Представим ситуацию, что мы деплоим по push-модели. В качестве платформы для запуска деплоя у нас используется Gitlab: в нём настроен пайплайн и джобы, разворачивающие приложения в разные окружения в Kubernetes
Какой бы инструмент мы не использовали (kubectl, helm), для манипуляций с ресурсами API нам в любом случае будет необходимо аутентифицироваться при выполнении запросов к Kubernetes. Для этого в запросе надо передать данные для аутентификации, будь то токен или сертификат. И тут возникает несколько вопросов:
-
Где хранить эти креды?
Хранить креды от кластера можно в Gitlab CI/CD Variables и подставлять в джобу деплоя, но тогда потенциально все пользователи будут деплоить с одними и теми же доступами
-
Как сделать так, чтобы у каждого пользователя были свои данные для доступа в кластер?
Можно было бы вручную запускать джобы деплоя и в параметры каждый раз подставлять свои аутентификационные данные, но, очевидно, такой подход неудобен и подходит далеко не всем
А что если сделать так, чтобы в качестве провайдера аутентификационных данных для Kubernetes выступал сам Gitlab? Тогда не надо было бы нигде хранить креды, и каждый пользователь мог бы аутентифицироваться в кубере под своей учёткой при запуске деплоя
Как получить переменные окружения процесса
Простой ответ: прочитав файл /proc/<pid>/environ
Однако таким образом можно получить только те переменные окружения, которые были заданы на момент создания процесса. Если же во время работы программа меняла/устанавливала новые/удаляла переменные окружения через, например, setenv / unsetenv, то эти изменения в файле отражены не будут. Эти значения можно уже будет достать только из оперативной памяти, либо если текущая программа вызовет другую через fork или exec - в таком случае для нового процесса будет заново проинициализирован /proc/<pid>/environ с переменными окружениям родителя/замещённого процесса
Почему так происходит?
Файл /proc/<pid>/environ находится в директории /proc, которая, по сути, предоставляет доступ к структурам данных ядра в оперативной памяти через специальный драйвер файловой системы procfs
Эта статья на Хабре https://habr.com/ru/post/675728/
Описание проблемы
Дано
- кластер k8s
- много приложений, которые пишут свои логи в stdout/stderr, а контейнерный движок (в данном случае docker) складывает их в файлы
- fluent-bit, запущенный на каждой ноде k8s. Он собирает логи, фильтрует их и отправляет в Loki
- loki - хранилище логов от Grafana Labs
В чём заключается проблема
При просмотре логов через Grafana (источник - Loki) видно, что логи приходят с сильной задержкой или часть логов вообще отсутствует. При просмотре через kubectl logs все логи на месте
Решение проблемы

Settings
-
Client ID
Уникальный идентификатор клиента
-
Name
Отображаемое имя (например, в окне согласия (Consent))
-
Description
Описание
-
Enabled
Вкл/Выкл
-
Always Display in Console
Всегда показываться клиента в списках приложений пользователя в Account Management Console
Keycloak Scopes OIDC
default - включен в scopes по-умолчанию
optional - включается в scopes при запроса
consent - отображать в окне согласия при запросе разрешения на аутентификацию у пользователя
scope - добавлять в список scope токена
OIDC
-
profile
default, consent, scope
mappers:
- profile, name, gender, locale, etc…
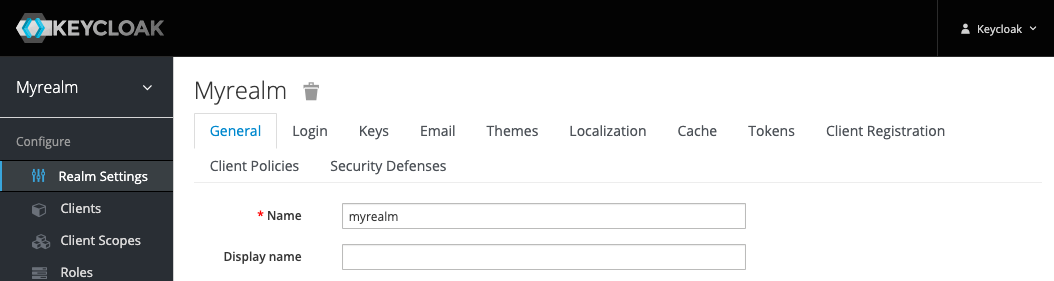
Realm Settings
General
-
Name
Название/ID реалма
-
Display name
Отображаемое имя
-
HTML Display name
Отображаемое имя с возможность использования html-тегов (например, добавление лого). Если задано, то имеет приоритет над Display name
-
Frontend URL
Позволяет для реалма задать отдельное доменное имя. Например, можно сделать такой матчинг
auth.example.com -> sso.example.com/auth/realms/myrealm. Обработкой занимается встроенный веб-сервер. То же самое можно реализовать через reverse-proxy, типа nginx, с установкойHostхидера при проксировании и “обрезанием” путей -
Enabled
Вкл/Выкл
-
User-Managed Access
Включить управление своими ресурсами в Account Management Console (auth/realms/myrealm/account/resource)
-
Endpoints
Ссылки OIDC/SAML, где можно получить все доступные точки входа для проктоколов
Оригинальный syslogd
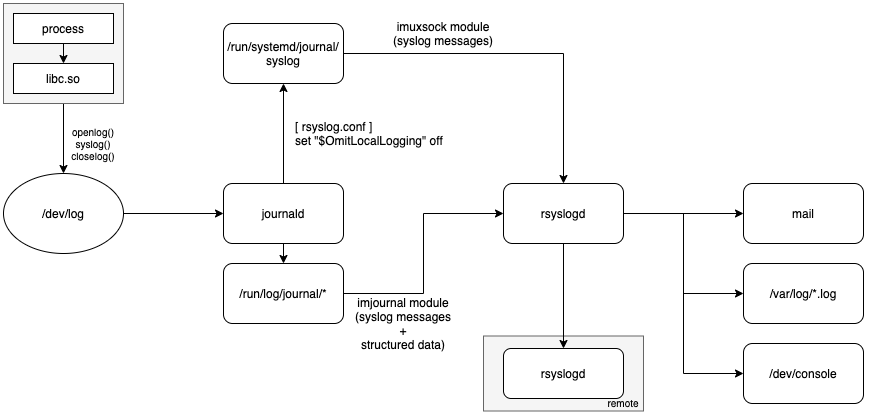
Cвязка journald + rsyslogd
Форматы syslog сообщений
RFC 3164 (устаревший)
RFC 3164 - The BSD Syslog Protocol
Описание формата сообщения
The first part is called the PRI, the second part is the HEADER, and the third part is the MSG. The total length of the packet MUST be 1024 bytes or less
Варианты запуска сборок
-
Shell executor
- Небезопасно, т.к. можно выполнять какие угодно docker команды на хосте, в т.ч. пробрасывать хостовые папки и запускать privileged контейнеры
-
docker-in-docker
- Изолированные друг от друга контейнеры, т.к. здесь child контейнеры от контейнера dind, а не от хостового docker.sock
- Необходим запуск с privileged (небезопасно)
-
Проброс docker.sock
- Все контейнеры - siblings (видят друг друга), т.к. запускается через хостовый docker
- Небезопасно, т.к. можно выполнять какие угодно docker команды на хосте, в т.ч. пробрасывать хостовые папки и запускать privileged контейнеры
-
buildah/buildkit/img
- Позволяют внутри докер контейнера запускать сборку образа без докер-демона
- Требуется unprivileged_userns_clone (user namespaces), у которого свои security-риски
- Синтаксис запуска отличается -> переучивать команду
-
kaniko
- Позволяют внутри докер контейнера запускать сборку образа без докер-демона
- Не поддерживается установка бинарника в свой образ. Необходимо использовать официальный образ
- Синтаксис запуска отличается -> переучивать команду
Потенциальные векторы атаки
-
Источник
- В сборке используется публичный образ, в котором в entrypoint выполняется команда проверки docker.sock и запуск контейнера через него
- При сборке в зависимостях (напрмер, node) скачивается зловред, который запускается в процессе сборки. Далее проверка docker.sock и запуск контейнера через него
-
Цель
- Закрепиться в системе. Через докер возможно установить свои бинарники и сервисы в систему
- Дальнейший скан сети и поиск уязвимостей для распространения и закрепления
Перезапустить kubelet
Контейнеры продолжают работать, но в момент синхронизации состояния подов с api-server поды могут переходить в состояние 0/1 Running, когда трафик на них перестаёт направляться
Остановить kubelet
Нода переходит в состояние NotReady, никаких событий на подах не происходит - они продолжают пребывать в состоянии 1/1 Running, но трафик на них перестаёт идти (из endpoint’ов сервисов удаляются IP адрес подов, которые находятся на “мёртвой” ноде).
Спустя указанный pod-eviction-timeout (5m по-умолчанию) для kube-controller-manager поды переходят в статус Terminating и начинают запускаться на живых воркерках. Поды будут продолжать находиться в статусе Terminating либо до старта kubelet, либо до удаления ноды из кластера. При этом не выгоняются поды DaemonSet и поды, поднятые kubelet’ом(kube-proxy, nginx-proxy, kube-flannel, nodelocaldns и т.п.)
Атуально для Akka HTTP начиная с версии 10.2.0
Github Issue: Add coordinated shutdown support
По-умолчанию, Akka при завершении (в т.ч. получении SIGTERM) запускает процесс Coordinated Shutdown, в рамках которого происходят последовательно несколько фаз:
- before-service-unbind
- service-unbind
- service-requests-done
- service-stop
- before-cluster-shutdown
- cluster-sharding-shutdown-region
- cluster-leave
- cluster-exiting
- cluster-exiting-done
- cluster-shutdown
- before-actor-system-terminate
- actor-system-terminate
В каждой фазе выполняются определённые действия и настроен таймаут, который можно переопределить и в течение которого эти действия должны завершиться. Если действия не успевают завершаться, то фаза заканчивается и начинается следующая
В рамках Akka HTTP нас в первую очередь интересуют следующие фазы
- service-unbind #перестаёт слушаться tcp порт и перестают приниматься новые соединения. Установленные соединения не разрываются
- service-requests-done #ожидается окончание запросов, которые в данный момент обрабатываются кодом и клиент ожидает на них ответ
- service-stop #закрываются все установленные соединения
По-умолчанию (default-phase-timeout = 5s), после unbind есть 5 секунд на завершение текущих запросов
При использовании Kubernetes, стоит принимать во внимание также его таймаут terminationGracePeriodSeconds, в течение которого будет ожидаться реакция на SIGTERM, после чего будет послан SIGKILL. По-умолчанию, он равен 30s
